Embracing Resilience: HackerOne's Approach to Disaster Recovery

Let's explore an essential yet often overlooked aspect: Disaster Recovery, or DR for short. It serves as our strategic response to external events beyond our control. I'll walk you through not just what DR means, but also how we put it into action at HackerOne, sharing insights into our team's practices and performance stats.
So, What Is Disaster Recovery?
In the dynamic world of tech, things can break – sometimes due to our actions, but it can also be due to external factors like provider outages. That's where Disaster Recovery (DR) comes in. It’s our blueprint for rapidly restoring to normal when the unexpected strikes. Consider it our contingency plan for events outside our control, from power outages to natural disasters. It helps the company get back to normal as quickly as possible.
The Plan in Action: Ensuring Continuity
What's our primary mission in a crisis as explained above? Get HackerOne up and running again, and do it quickly. We start with our core platform because that's the heart of our operation. Once that's secured, our attention shifts to other vital services like our Gitlab instance and several others. To make sure we're efficient and effective, we follow a tier-based catalog that ranks each service by importance. This approach helps us all to be on the same page about what needs to be up and running first.
While our Disaster Recovery Plan is an internal document, it's accessible to every member of our HackerOnie. Why keep such valuable insights under wraps? This plan is more than a bunch of procedures – it’s our blueprint for maintaining top-notch data security and system functionality, especially when challenges arise.
By ensuring that all our team members can access this plan, we’re not just sharing information; we’re fostering a culture where disaster recovery is a shared responsibility. This approach underlines our dedication to keeping our systems secure, operational, and resilient, regardless of the challenges we might face.
Annual Drills: Beyond Compliance
Sure, frameworks like ISO 27001 and SOC 2 specify that we need to run disaster recovery tests. But honestly, for us, it's way more than just ticking off a box for compliance. We see these regular disaster recovery drills as a key part of our culture, just like we view regular credential rotations. It's all about staying sharp and up-to-date.
Think of it as our pledge to not just follow, but lead in best practices. We're not just looking inward, though; we're aiming to set a standard that inspires our customers, too. By rigorously testing and updating our disaster recovery strategies, we're not just ensuring our own resilience; we're also showcasing a model of preparedness and proactiveness.
In short, these exercises are a chance for us to reinforce our defenses and demonstrate to our customers the value of staying ahead of the game. It’s about building a community that values vigilance and readiness, not just because a rule book says so, but because it’s the smart thing to do.
Targets and Performance: Striving for Excellence
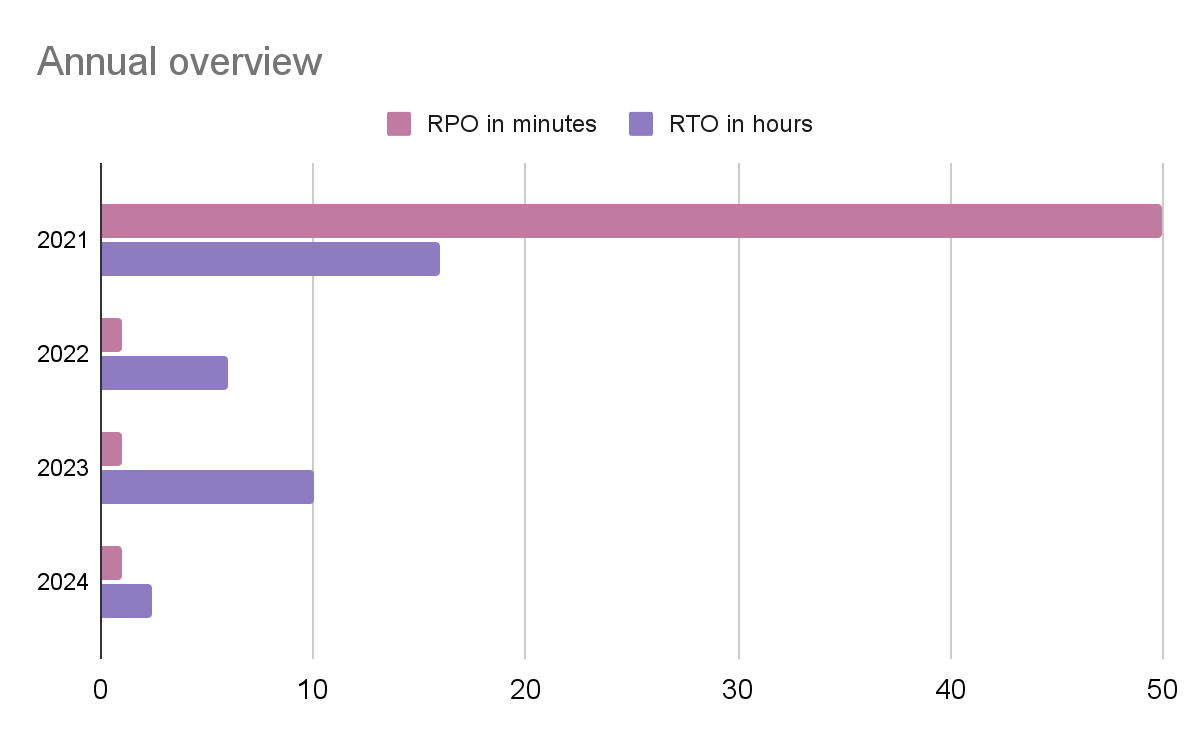
In our pursuit of disaster recovery mastery, HackerOne has set ambitious goals tracked by two key metrics: the Recovery Point Objective (RPO) and the Recovery Time Objective (RTO). A Recovery Point Objective is the maximum time permitted for data to be restored, which may or may not mean data loss. The Recovery Time Objective is the targeted duration between the event of failure and the point where operations resume. Our RPO targets 24 hours. Our data, being some of our customers' most valuable and sensitive data, targets seconds. Internally, we strive for even greater speed - RPO in seconds and RTO in hours, guided by the mantra "As fast as possible." This drive for rapid response has led to significant strides.
From achieving a 50-minute RPO and 16-hour RTO in 2021, we've accelerated to an RPO of less than a second and an RTO of just over 6 hours in 2022. The 2023 exercise, a venture into more complex scenarios with extended duration, was both a challenge and a triumph, leading to the immediate identification and resolution of 10 improvement areas. Here are two examples of the improvements we made: We enhanced our code deployment strategy to increase flexibility in likely scenarios during disaster recovery, and we also developed internal tools to automate the mundane and error-prone tasks required in these situations. This continuous journey of setting and surpassing benchmarks shows our progress and cements our commitment to delivering unparalleled reliability and excellence in disaster recovery. After implementing these enhancements, we recorded an RPO of less than a minute and an RTO of two hours and 41 minutes, marking significant progress. This is a big win!
Yet, we must ask ourselves if this is sufficient. While we meet compliance requirements and already have an awesome new time record, is that enough? Should we integrate more realistic scenarios, such as adding new components to our exercises, or aim for faster recovery times?
Continuous Improvement: The Road Ahead
Drawing from our experiences and the lessons learned in previous exercises, we're committed to evolving and enhancing our disaster recovery plans. The focus now is to broaden the scope of our disaster recovery exercises, integrating more critical services as dictated by our tier-based service catalog. This expansion will include key services like GitLab and others, ensuring a comprehensive and robust disaster recovery strategy. By continuously incorporating new elements and refining existing ones, like our search service, we aim to not only meet but exceed disaster recovery standards, keeping pace with the dynamic nature of our services and their importance to our overall operations.
Learning With a Dash of Fun
Our disaster recovery exercises strike a unique balance between serious preparation and fun learning. Each year, we infuse our simulations with creative scenarios, such as blizzards, tidal waves, or alien threats to our data centers.
Example of our introduction of the Disaster last year:
“In a shocking turn of events, the AWS us-west-2 datacenter in Oregon fell victim to a targeted invasion by green-skinned extraterrestrial beings. The enigmatic assault left the once bustling hub of digital infrastructure in ruins, with the invaders seemingly focusing their efforts solely on this critical data center. Eyewitnesses reported a surreal scene as the aliens descended upon the facility, causing widespread destruction before vanishing without a trace.”
This approach not only keeps the team engaged but also sharpens our skills in a variety of unforeseen situations. But it's not just about the fun; communication plays a pivotal role in our disaster recovery strategy.
We believe that effective disaster recovery is a collaborative effort that requires transparent and constant communication throughout the organization. From the start of a disaster recovery exercise to the final presentation of our findings, we ensure everyone is informed and involved. This dual focus on engaging learning experiences and clear communication fosters a culture of preparedness and teamwork, essential for any successful disaster recovery plan.
Ready for the Real Challenges
At HackerOne, we view disaster recovery as more than just a set of protocols; it's our pledge to be fully equipped for real-life challenges. It's a team-wide mission, bringing us together in a shared goal: to not only anticipate but tackle any obstacle skillfully. As the world of cybersecurity constantly evolves, being prepared is crucial. For us, readiness isn't merely a choice; it's an essential part of who we are, ensuring we stay resilient and responsive in the face of adversity.
I invite you to embrace this practice in your teams. How well are you prepared for when disaster strikes? Regularly testing and updating your disaster recovery strategies is not just good practice – it’s essential. Prepare, practice, and stay ahead.
In cybersecurity, the best defense is a proactive approach. Let's make resilience and preparedness our collective goal.
The Ultimate Guide to Managing Ethical and Security Risks in AI
